The assumption is made that this can be some kind of test of memory. The experiment designers seem to have assumed that when a mouse goes to compartments already visited, the mouse will kind of recognize those compartments, and be less likely to explore them, perhaps having some kind of "I need not explore something I've already explored" experience. This is a very dubious assumption.
It's as if the designers of this apparatus were assuming that a mouse is thinking something like this:
"My, my, these experimenter guys have given me six compartments to explore! Well, there's no point in exploring any of the three compartments I already explored. Been there, done that. So I guess I'll spend more time exploring the compartments I have not been to. I'm sure there will just be exactly the same stuff in the three compartments I've already explored, and that I need not spend any time re-exploring them to check whether there's something new in them."
The assumptions behind this experimental design seem very dubious. It is not at all clear that a mouse would have any such tendency to recognize previous compartments the mouse had been in, and to think that such previously visited compartments were less worthy of exploration.
The best way to test whether such assumptions are correct is by experimentation. Without doing anything to modify a mouse's memory, you can simply test normal mice, and see whether they are less likely to spend time in compartments they previously visited. Figure 2 of the paper "The free-exploratory paradigm as a model of trait anxiety in rats: Test–retest reliability" gives us a good graph testing how reliable this "free-exploratory paradigm" is, using a 10-minute observation period. The test involved 30 mice:

The figure suggests that this "free-exploratory paradigm" is not a very reliable technique for judging whether mice remembered something. In the first test, there was no tendency of the mice to spend more time exploring the unexplored compartments. In the second test there was only a slightly greater tendency of the mice to explore the previously unexplored compartments. Overall the mice spent only 55 percent of their time in the previously unexplored compartments, versus 45 percent of their time in the previously explored compartments.
What is the relevance of this? It means that any neuroscience experiment that is based on this "free-exploratory paradigm" and fails to use a very large study group size is worthless. An example of a worthless study based on such a technique is the study hailed by a press release this year, one with a headline of "Boosting brain’s waste removal system improves memory in old mice." No good evidence for any such thing was produced.
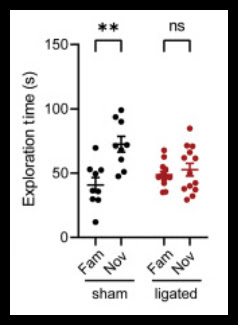
The press release is promoting a study called "Meningeal lymphatics-microglia axis regulates synaptic physiology" which you can read here. That study all hinges upon an attempt to measure recall or recognition by mice, using something called a Y-maze, which consists of 3 compartments, the overall structure being shaped like the letter Y. The Y-maze (not actually a maze) is an implementation of the unreliable "free-exploratory paradigm" measurement technique described above. The study used a study group size of only 17 mice. But since the "free-exploratory paradigm" requires study group sizes much larger than 17 to provide any compelling evidence for anything, the study utterly fails as reliable evidence.
Using a binomial probability calculator, we can compute the chance of getting a false alarm, using a measurement technique like the "free-exploratory paradigm." Figure 1C of the paper "Meningeal lymphatics-microglia axis regulates synaptic physiology" shows only a very slight difference between the "free-exploratory paradigm" performance for the modified mice and the unmodified mice:
Given this "free-exploratory paradigm" that is something like only 55% effective in measuring recognition memory, the probability of getting results like this by chance (even if the experimental intervention has no real effect) is roughly the same as what we see in the calculation below:
Produced using the calculator here
The chance of getting purely by chance a result like the result reported in the paper is roughly the 1 in 3 shown in the bottom line above. When we consider publication bias and the "file drawer" effect, getting a result like the reported result means nothing. Why? Because it would be merely necessary to try the experiment a few times before you could report a success, even if the experimental intervention had no effectiveness whatsoever.
We should never be persuaded by results like this, because what could easily be happening is something like this:
- Team 1 at some college tries this intervention, seeing no effect. Realizing null results are hard to get published, Team 1 files its results in its file drawer.
- Team 2 at some other college tries this intervention, seeing no effect. Realizing null results are hard to get published, Team 2 files its results in its file drawer.
- Team 3 tries this intervention, seeing a "statistically significant" effect of a type you would get in maybe 1 time in three tries. Team 3 submits its positive result for publication, and gets a paper published.
In a scenario like the one above, there is no real evidence for the effect. All that is happening is a result like what we would expect to get by chance, even if the effect does not exist.
What we must also consider is that any researcher wanting to tilt the scales a bit can do so when using this free-exploratory paradigm. When these type of experiments are done, the compartments are not empty. Instead some items are put in the compartments. There is no standard protocol about what is put in the compartments. A researcher can put in the compartments anything he wants. Each compartment is supposed to have a few items, but there is no standard number or size of items to use. So imagine you are trying to show what looks like a loss of memory recognition in some experiment using this free-exploratory paradigm. All you need to do is put some less interesting items or fewer items in the unexplored compartments. And if you want to show what looks like an improvement in memory, you need merely put some more interesting items or more items in the unexplored compartments. Since there is no standard protocol used using this free-exploratory paradigm, an experimenter can get whatever result he wants, by varying conditions in the compartments.
At the top I give a graph from the
the paper "The free-exploratory paradigm as a model of trait anxiety in rats: Test–retest reliability," which showed a mere 55% reliability using this free-exploratory paradigm in ten minute tests, but a greater reliability with 15 minute tests. How long a time length does
the paper "Meningeal lymphatics-microglia axis regulates synaptic physiology" use? Only 2 or 3 minutes. I doubt very much that there is any evidence that such tests have much more than 50% reliability with such a short time span. This is a common defect of both the free-exploratory paradigm and the "freezing behavior" approach: they can produce wildly different results depending on the time interval used. And since there is no standard for a time interval used, an experimenter can use any time interval, including some interval that has not been verified as having any decent reliability. This is all the more reason to think that such methods are "see whatever you are hoping to see" affairs that have no validity as solid measurement techniques for measuring recall or recognition in rodents. I can imagine how things might work: an animal may be tested for 10 minutes using either technique; and if the experimenter doesn't like the result in the full ten minutes, he can simply report in his paper on the first 5 minutes; and if he does not like that result, he can report in his paper on only the first three minutes; and so on and so forth. If the paper is not a pre-registered paper committing itself to an exact detailed observational protocol, an experimenter can get away with that; and few neuroscience experiments these days follow such a pre-registered approach. Today's experimental neuroscience is such a standard-weak freewheeling farce of loose and bad methods that it is probably considered permissible to gather a particular type of data for ten minutes, and then report on only the results gathered in any arbitrary fraction of those minutes, as long as you start from the beginning.
In the paper here, it says, "In the Y-maze continuous procedure, the rat or mouse is placed in the maze for a
defined period (typically 5 min) and the sequence of arm choices
is recorded." But in the paper "Meningeal lymphatics-microglia axis regulates synaptic physiology" discussed above, the Y-maze test time was only 3 minutes; so we have a deviation from the typical procedure with this device. The same paper tells us "Hippocampectomized animals notoriously adopt side preferences,
e.g., always turning right on a T-maze," something we can suspect may also be true in a Y-maze, giving another reason for doubting the suitability of such tests (both examples of the free exploratory paradigm) for testing memory modifications such as hippocampus lesions.
The sad truth is that experiments done with this free-exploratory paradigm (such as a Y-maze experiment or a T-maze experiment) are worthless unless they use large study group sizes of at least 30 subjects per study group, and also an exact protocol that has been proven to be a reliable method of measuring recall or recognition in rodents. So we can have no confidence in the results reported by
the study referred to above, the one called "Meningeal lymphatics-microglia axis regulates synaptic physiology" which you can read here. That study all hinges upon an attempt to measure recall or recognition using the free exploratory paradigm, but does not use a large enough study group size to produce a reliable result using that paradigm. And we have no evidence of exactly following a precise protocol proven to be a reliable measure of rodent recall.
Neither the free-exploratory paradigm (such as Y-maze experiments) nor "freezing behavior" experiments produce reliable results when anyone uses study group sizes smaller than 30. Both are poor, unreliable ways of measuring recall or recognition in rodents, allowing so much flexibility and opportunity for bias that it's just a "see whatever you want to see" type of affair. But what kind of methods tend to produce good, reliable results in measuring recall in rodents? I can think of four:
(1) A "find the food reward" maze technique like the one described above, in which you measure how many seconds a rodent takes to find a food reward, using a maze the rodent had been previously trained on to find a food reward.
(2) The Morris water maze test, a widely used test that is not really a maze test, but a test of how well a rodent will remember to find a submerged platform after previously being trained to find that platform in a water tank. However a
scientific paper cautions that the Morris water maze test may not work well with many strain of mice, saying this: "Neuroscientists have been warned that many strains [of mice] perform poorly on the submerged-platform water escape test task, which is better suited to rats than to mice, yet it is used widely for the study of
memory in mice."
Another paper gives a similar reason for thinking that the Morris water maze test (MWM) may only be suitable for rats, stating this: "Interestingly, when MWM data were analyzed in a large dataset of 1500 mice by factor analysis, the principle factors
affecting MWM performance in mice were noncognitive
(Lipp and Wolfer 1998).... It is important to note
that this is not the case in rats, but the fact that performance
factors are salient in mice provides an important cautionary
note when interpreting mouse MWM data." But see the Appendix for reasons for doubting many uses of the Morris water maze test (MWM), even when it is done with rats.
(3) A fear recall technique, measuring spikes in heart rate. The heart rate of a mouse will very dramatically spike when the mouse is afraid. So a mouse can be trained to fear some painful stimulus such as a shock plate. Then the mouse can be placed in a cage that has the fear-inducing stimulus. If the mouse's heart rate speeds up very much, that is good evidence that the mouse has remembered the fear-inducing stimulus such as the shock plate.
(4) The Fear Stimulus Avoidance technique depicted below, which does not require heart-rate measurement. After being trained to fear some fearful stimulus such as a shock plate, the mouse can be placed in a cage that offers two paths to a food reward: one path that requires going through the fearful stimulus such as a shock plate, and another other path to the food reward that is physically much harder to traverse, such as a path requiring climbing steep stairs. If a rodent takes the much harder path to get to the food reward, that is good evidence that it remembered the pain caused by the fearful stimulus such as the shock plate.

The mere use of a more reliable measurement technique does not guarantee a reliable result. While the Morris water maze test can be a reliable test when it is done in a straightforward way with rats, it must be used with a big enough study group size, and very many neuroscience experimenters fail to do that. A
paper notes the problem, stating this about the Morris Water Maze test (MWM):
"Many MWM experiments are reported with small
group sizes. In our experience with the MWM and other water
mazes, group sizes less than 10 can be unreliable and we use
15 to 20 animals per group, especially for mice, whose performance in learning and memory tests tends to be more variable than for rats. It is noteworthy that regulatory authorities
require that safety studies have 20 or 25 animals per group.
This number is for each of at least four groups (control and
three dose levels) (Food and Drug Administration 2007;
Gad 2009; Tyl and Marr 2012). Such group sizes are used
by the US Environmental Protection Agency, the US Food
and Drug Administration, the Organization for Economic
Cooperation and Development, and Japanese and European
Union regulatory agencies. Although the 3 Rs (reduce, refine,
and replace) are worthwhile goals in the use of animals in
research, it is not a justification to underpower experiments
and run the risk of false positives, which, in the long run,
cost more time, more animals, and more money to prove or
disprove."
Postscript: The term "spontaneous alternation behavior" is used to describe a case in which a rodent that has explored one arm of a T-maze or Y-maze is exposed to the maze again, and switches to a different arm. The higher the average "spontaneous alternation percentage" is (the higher above 50%) in control rodents, the more reliable such a T-maze or Y-maze is as a test of memory; and a well-established average "spontaneous alternation percentage" of maybe 75% would indicate a pretty good test. The graph
here shows female controls showing such behavior only 55% of the time, and male controls showing such behavior 60% of the time; but the sample size is only 5. Figure 4 of the paper
here shows control rats using such "spontaneous alternation behavior" only 50% of the time in a Y-maze. The sample size is only 6. The graph
here shows only about 60% "spontaneous alternation behavior" for 9 control rodents tested with a Y-maze. Figure 3 of the paper
here shows male control rodents showing such "spontaneous alternation behavior" only about 50% of the time. Figure 1 of the paper
here shows a "spontaneous alternation percentage" of only about 57% for 6 control mice. In Figure 1 of the paper
here, the "spontaneous alternation percentage" is only 35% in control rodents. These results are consistent with my claim above that such tests are not-very-reliable tests requiring large study group sizes to produce even borderline, modest evidence of a memory effect.
The problem with a measurement technique that only gives you the right answer about 60% of the time is that when using such a technique it is really easy to get false alarms, particularly with small study group sizes. So you have no basis for strong confidence in some study testing only about 15 rats using a T-maze or a Y-maze.
Appendix: The Morris water maze test (MWM) can be a reliable technique, when it is used with rats, in a straightforward way, with an adequate study group size. By "in a straightforward way," I mean doing something such as simply recording the time it took rats placed in the Morris water maze to reach the submerged platform. This time is called the "escape latency" time. When the Morris water maze test is done in a reliable way, we will see a simple bar graph comparing this "escape latency" time for two different groups, an experimental group and a control group. That "escape latency" is simply the average time it took a rat in the group to reach the submerged platform. The graph might look like the graph below. If the study group size was large enough, this might be good evidence that the experimental group was remembering better than the control group.

But there are many studies that use the Morris water maze test (MWM) in an objectionable way, doing analytics in a way that is not straightforward, in a way that smells like "keep torturing the data until it confesses." For example, we may see charts showing how much time rats spent in a particular quadrant of the Morris water maze. Or we may see charts plotting the exact path that particular rats traversed in the Morris water maze test. When data analysis this complicated and arbitrary starts going on, there then occurs a plummeting of the reliability the Morris water maze (MWM) as a test of memory. Whenever you are allowed to analyze data in very many different ways, you will be able to find some desired difference between a control group and an experimental group. Finding that difference will be as easy getting a desired "heads" flip of a coin when you are free to flip the coin a dozen times.
Referring to the scientific paper
here, the Wikipedia.org
article on the Morris water maze test (MWM) now states the following:
"Changes in measures of Morris water navigation task performance may not necessarily reflect specific impairments in mechanisms of spatial learning or memory. The reason for a longer time spent looking for the platform, or the lack of searching in the target quadrant, may not necessarily have to do with an effect on the rat's or mouse's spatial memory, but can be due to other factors. For example, a large study of Morris water navigation task performance in mice concluded that almost half of all variance in performance scores was due to differences in thigmotaxis, the tendency of mice to stay close to the walls of the pool. About 20% of the variability was explained by differing tendencies of mice to float passively in the water until 'rescued' by the experimenter. Differences in spatial memory were only the third factor, explaining just 13% of the variation between animals' performance.[16]"
It seems the Morris water maze test is not a reliable test of memory in mice, although it might be fairly reliable when testing rats.






No comments:
Post a Comment